
The Ultimate Guide to Text-to-Speech APIs in 2024: From Basic TTS to Advanced Voice Cloning
Written on . Posted in AI.
Voice technologies have evolved with Text-to-Speech (TTS), which translates written text into natural-sounding speech. This innovation fuels applications that improve accessibility, educational tools, and interactive digital experiences.
TTS is necessary for those interested in improving accessibility, creating educational tools, or developing new voice assistant capabilities. Whether you're improving apps for accessibility, creating engaging e-learning content, or building your own virtual assistants, choosing the right TTS API is key.
This guide explores the latest in TTS, focusing on advanced voice cloning technologies available in 2024.
Understanding Text-to-Speech Technology
Text-to-speech (TTS) technology converts written text into spoken words. Initially, TTS systems used pre-recorded speech pieces or basic synthetic voice models. However, advancements in generative AI have led to the creation of more natural-sounding and flexible neural TTS systems.
These advanced systems use algorithms and machine learning techniques to read text and generate human-like speech, helping computers and devices interact with users more naturally.

A recent development in TTS is voice cloning, which creates synthetic voices that mimic specific individuals. This technology offers personalized voice experiences, such as custom voiceovers, improved virtual assistants, and more engaging content.
TTS has become a popular field of AI, providing creative solutions for creators and businesses aiming to use human-like speech in their interactions.
Use Cases of Text-to-Speech (TTS)
There are many use cases of Text to speech in real life:
Language Learning:
TTS plays a significant role in language learning programs and applications. It offers multilingual support across a wide range of languages, including English, Chinese, Spanish, Japanese, French, and more.
Language learners can benefit from TTS by practicing pronunciation, listening to native speakers, and improving skills through audio-based learning experiences.
Audiobooks and Podcasts:
TTS technology is used to convert written content, such as books and articles, into audio formats like audiobooks and podcasts. This application is helpful to individuals who prefer listening to content rather than reading it.
TTS-generated audio files provide a convenient and accessible way for users to consume literature, news, and other media on the go.
Voiceovers for Videos:
In video production, TTS technology is used to create voiceovers that accompany visual content. This includes narrating instructional videos, documentaries, and presentations.
TTS-generated voiceovers ensure consistent and clear audio narration, enhancing the viewer's understanding and engagement with the video material.
Educational Tools:
TTS serves as a valuable educational tool by integrating audio elements into learning materials. It enhances the accessibility and engagement of educational content, making it easier for students to absorb information through listening.
TTS-enabled educational tools include digital textbooks, language learning apps, and interactive learning platforms that cater to diverse learning styles.
Assistive Technology for Disabilities:
TTS technology is an important tool for individuals with disabilities such as dyslexia or visual impairments. By converting written text into spoken words, TTS assists in improving text understanding through auditory means.

This accessibility feature assures that users can consume written content more effectively, improving their overall access to information.
Customer Service Bots:
In customer service and support, TTS powers AI-driven chatbots and virtual assistants. These bots interact with customers using natural-sounding voices, providing automated responses to inquiries, handling routine tasks, and improving overall service efficiency.
TTS-enabled customer service bots offer a seamless and personalized user experience, enhancing customer satisfaction and retention.
Navigation Systems:
TTS technology is integrated into navigation and GPS systems to provide spoken directions and guidance to users. Whether in-car navigation systems or mobile navigation apps.
TTS ensures that drivers and pedestrians receive clear, real-time instructions for navigation. This improves safety, convenience, and usability during travel and exploration.
Subtitles and Transcription:
TTS assists in generating subtitles and transcription for videos and audio content. By converting spoken words into written text, TTS improves accessibility for viewers who are deaf or hard of hearing.
Additionally, TTS-generated subtitles make multimedia content more accessible to international audiences, overcoming language barriers and broadening content reach.
Top Text-to-Speech APIs of 2024
Here are the Top 4 Text to speech APIs of 2024:
1. ModelsLab Voice Cloning
Key Features:
Advanced voice cloning technology
Create custom voices with minimal training data
High-quality, natural-sounding output
Flexible API for easy integration
Pricing: Custom pricing based on project requirements
Best For: Personalized voice experiences, virtual assistants, and creative applications
ModelsLab's voice cloning technology stands out for its ability to create highly realistic custom voices with minimal input. This opens up new possibilities for personalized audio content, virtual influencers, and more.
2. Google Cloud Text-to-Speech
Key Features:
220+ voices across 40+ languages and variants
WaveNet voices for natural-sounding speech
Customizable speaking rate and pitch
Pricing: Pay-as-you-go model, starting at $4 per 1 million characters for standard voices
Best For Large-scale applications requiring multiple languages
3. Amazon Polly
Key Features:
60+ voices across 30+ languages
Neural TTS voices for lifelike speech
SSML support for fine-tuned control
Pricing: $4 per 1 million characters for standard voices, $16 per 1 million characters for neural voices
Best For: AWS ecosystem integration and e-commerce applications
4. Microsoft Azure Text-to-Speech
Key Features:
400+ neural voices across 140+ languages and variants
Custom voice creation
Real-time streaming and batch processing
Pricing: Free tier available, then $4 per 1 million characters for standard voices
Best For: Microsoft-centric development environments and accessibility features
ModelLab's Text-to-Audio API Implementation Guide
ModelLab’s Text to Audio API allows users to create audio files from text inputs, either by cloning a voice from a provided audio URL or by using a pre-created voice ID.
The Text to Audio endpoint lets you generate audio by sending a text prompt along with a valid audio URL or a pre-created voice ID. The generated audio will mimic the voice from the provided URL or voice ID.
This guide will provide a detailed implementation example and explain the necessary parameters and responses.
Request
Make a POST request in Postman to the endpoint and pass the required parameters as a request body.

Example Implementation
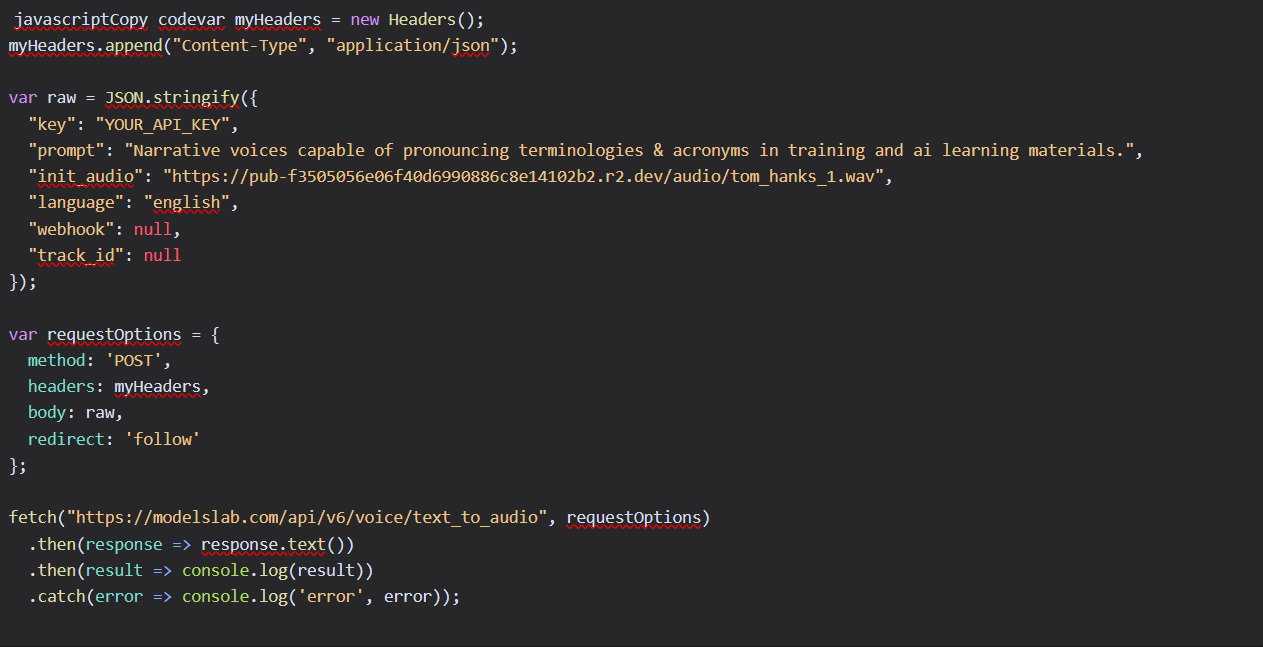
Here's a basic example of how to implement ModelLab's voice cloning API:
Write
API Key. You can find your API Key Here:

Write
prompt(Text you want to convert)Include Voice Sample (
init_audio).Note: You can either pass
init_audioorvoice_id. However, if both are passed,init_audiotakes precedence.Adjust parameters as per your need. For more information about
parameters, Visit Modelslab's API Docs.

JavaScript Implementation Example
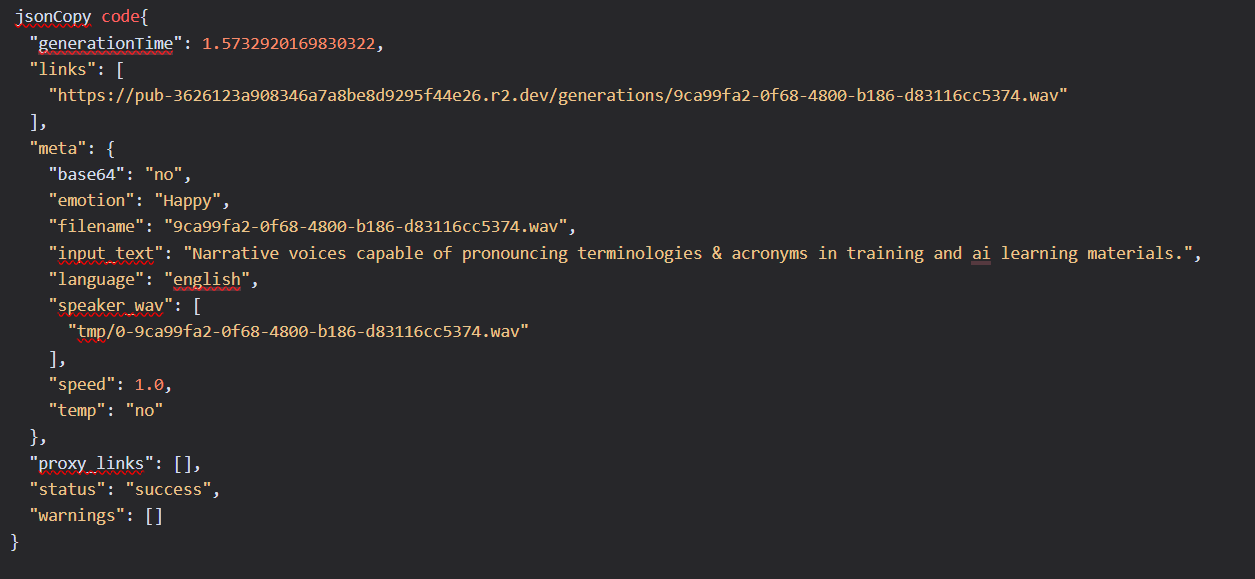
Response Example
Still confused? Don't Worry! Watch our Text to Speech demo video.
Key Considerations When Selecting a TTS API
When selecting a TTS API, consider the following factors:
Voice Quality
Listen to voice samples from various TTS APIs.
Choose an API that provides natural-sounding voices suitable for your application.
Language Support
Ensure the API supports all the languages you need.
Check for regional accents and dialects if necessary.
Customization Options
Look for APIs that allow adjustments to speech rate, pitch, and emphasis.
Advanced APIs may offer emotional tone and style adjustments.
Integration Ease
Check for comprehensive documentation, SDKs, and example code.
Good customer support is crucial for troubleshooting and guidance.
Scalability
Consider your current and future volume needs.
Ensure the API can handle your expected traffic and usage patterns.
Cost
Consider your current and future volume needs.
Ensure the API can handle your expected traffic and usage patterns.
The Future of Text-to-Speech and Voice Cloning
As we look ahead, several trends are shaping the future of Text-to-Speech (TTS) technology and voice cloning. These advancements promise to enrich the capabilities and applications of TTS systems, making them more universal, expressive, and ethical.
Emotional Intelligence in TTS Systems
One of the most exciting trends in TTS technology is the incorporation of emotional intelligence. Traditional TTS systems have been limited to producing neutral-sounding speech, which can be boring and lack the expressive nuances found in natural human speech.
However, future TTS systems seek to convey a wider range of emotions, such as happiness, sadness, anger, and excitement.
Real-Time Voice Cloning
Real-time voice cloning is a groundbreaking advancement that enables the instant replication of a person's voice. This technology allows for the creation of personalized and interactive audio experiences.
Content creators can use real-time voice cloning to produce unique audio content on the fly, from live voiceovers to real-time podcasting.
Multilingual Voices
The ability to seamlessly switch between languages while maintaining the same voice is a significant trend in TTS technology. This feature is particularly valuable in our increasingly globalized world, where communication across languages is essential.
Multilingual TTS systems can break down language barriers, facilitating communication in international settings, such as customer support, education, and global business.
Ethical Considerations
As voice cloning and TTS technology become more advanced and widespread, ethical considerations will play a critical role in their development and deployment. Ensuring responsible use and addressing potential misuse are paramount.
Addressing ethical concerns can help build user trust and acceptance of TTS and voice cloning technologies, paving the way for their broader adoption.
Conclusion
Text-to-speech (TTS) technology is evolving rapidly, with solutions ranging from basic TTS to advanced voice cloning. While traditional TTS APIs are present, ModelLab's voice cloning is redefining the boundaries of what's possible.
These advanced capabilities allow for the creation of custom, natural-sounding voices that can significantly improve user experiences across various platforms.
When choosing a TTS solution, think beyond now. Unique voices can set your app apart in a voice-centric world. From audiobooks to virtual assistants, ModelLab's advanced TTS can elevate your project to new heights.