
How LLMs work, clearly explained
Written on . Posted in AI.
Imagine being able to converse with a highly knowledgeable entity capable of understanding and generating human-like text on virtually any topic. This is the remarkable capability offered by large language models (LLMs), a revolutionary development in the field of artificial intelligence (AI) that has captured the attention of researchers, tech giants, and the general public alike.
LLMs are a type of AI system that can process and generate human-like text with remarkable fluency and coherence. These models are trained on vast amounts of data, allowing them to understand and produce language in a way that mimics human communication. From answering complex queries to writing creative stories, and even coding, LLMs are pushing the boundaries of what was once thought possible with natural language processing (NLP).
The significance of LLMs cannot be overstated. They have the potential to revolutionize industries ranging from customer service and content creation to education and healthcare. Imagine virtual assistants that can engage in nuanced conversations, tutoring systems that can adapt to individual learning styles, or even AI-powered writers capable of crafting compelling narratives. The possibilities are endless, and LLMs are at the forefront of this transformation.
But how do these language marvels actually work? What lies beneath the surface of their seemingly human-like responses? We'll dive into the fascinating world of LLMs, unraveling the intricate mechanisms that power their remarkable language abilities.
The Building Blocks: Neural Networks
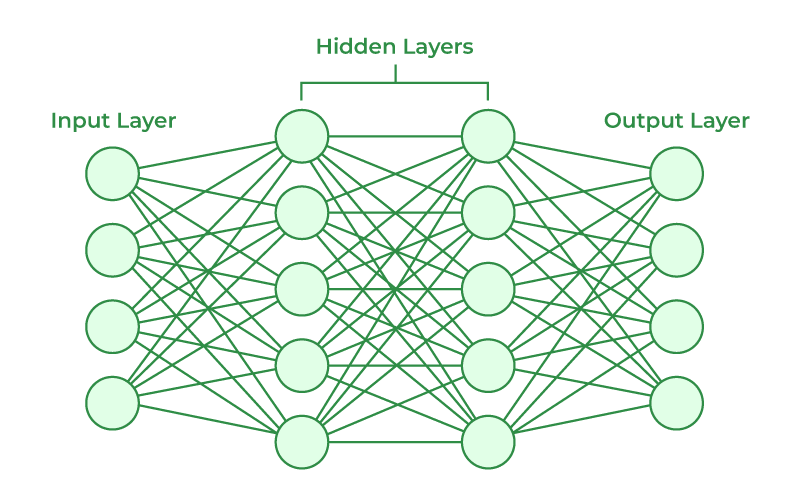
At the core of large language models lies a powerful computational architecture known as neural networks. These networks are loosely inspired by the structure and function of the human brain, consisting of interconnected units called neurons that process information in parallel.
Source: Geeks4Geeks
Just as the human brain is composed of billions of neurons that transmit signals through intricate networks of connections, neural networks in LLMs are made up of artificial "neurons" organized into layers. Each neuron receives inputs from other neurons, performs a simple computation, and passes the result to the next layer.
But how do these networks "learn" to understand and generate language? The key lies in the concept of adjustable connections between neurons, known as weights and biases. During the training process, these weights and biases are continuously fine-tuned based on the data the network is exposed to, allowing it to gradually improve its performance on a specific task.
Imagine a neural network as a vast landscape of hills and valleys, where each point represents a set of weight and bias values. The goal of training is to find the optimal combination of weights and biases that represents the "lowest point" in this landscape, corresponding to the most accurate output for a given input.
This optimization process is achieved through a technique called backpropagation, which calculates the error between the network's output and the desired output, and then adjusts the weights and biases accordingly. It's a bit like hiking through a mountainous terrain, constantly adjusting your steps based on the feedback from your surroundings to reach the desired destination.
Over countless iterations of exposure to language data and adjustments to weights and biases, the neural network gradually "learns" to recognize patterns, make predictions, and generate coherent text. It's a remarkable process that mimics the way the human brain adapts and learns from experience, but on a scale and complexity that surpasses our biological capabilities.
The Power of Language: Tokenization and Embeddings
While neural networks excel at processing numerical data, language is inherently symbolic and textual. To bridge this gap, LLMs employ a clever technique known as tokenization, which converts written text into a numerical representation that can be understood by the model.
Imagine you're trying to explain the concept of "dog" to someone who speaks a completely different language. One approach would be to break down the word into individual components or "tokens" that they can understand. For example, you might use symbols or drawings to represent the four legs, fur, tail, and other distinguishing features of a dog.
Similarly, tokenization breaks down text into smaller units, such as words, subwords, or even individual characters, and assigns each unit a unique numerical value or token. This process allows the model to treat language as a sequence of numbers, which can then be processed by the neural network.
However, tokenization alone is not enough to capture the nuances and relationships within language. This is where embeddings come into play. Embeddings are dense numerical representations of tokens that encode their meaning and context within a high-dimensional vector space.
Imagine a vast multidimensional space where each token is represented as a point, and tokens with similar meanings or contexts are clustered together. In this space, the relationships between words and their contexts become evident, allowing the model to understand and generate coherent language.
For example, the embeddings for the words "king" and "queen" would be located close together in this vector space, reflecting their semantic similarity as royalty terms. Conversely, the embeddings for "king" and "apple" would be farther apart, indicating their vastly different meanings and contexts.
By combining tokenization and embeddings, LLMs can effectively translate the complexities of human language into a numerical format that can be processed and learned by their neural network architectures. This powerful technique allows these models to capture the subtleties and nuances of language, enabling them to generate human-like text with remarkable fluency and coherence.
The Architecture of LLMs: Transformers and Attention Mechanisms
At the heart of modern large language models lies a revolutionary neural network architecture called the Transformer. This architectural breakthrough, introduced in 2017, has played a pivotal role in the remarkable performance of LLMs.
Traditional neural networks process language sequentially, meaning they process words or tokens one by one, in a strict order. However, the Transformer architecture takes a different approach, using a mechanism called self-attention to weigh the importance of different parts of the input sequence when processing each element.
Imagine you're trying to understand a complex sentence with multiple clauses and modifiers. Your brain doesn't process each word in isolation; instead, it constantly refers back to relevant words and phrases, building connections and understanding the relationships between different parts of the sentence.
The self-attention mechanism in Transformers works in a similar way. When processing a specific word or token, the model weighs its relevance and importance by "attending" to other words in the input sequence. This allows the model to capture long-range dependencies and relationships between different parts of the text, something that traditional sequential models often struggled with.
But how does this attention mechanism work in practice? Essentially, the self-attention layer computes a set of attention scores that determine how much focus or "attention" should be given to each part of the input sequence when processing a specific element. These scores are calculated based on the similarities between the current element and the other elements in the sequence.
For example, when processing the word "queen" in a sentence, the self-attention mechanism might assign higher attention scores to words like "king" and "royal," allowing the model to better understand the context and relationships within the sentence.
This attention mechanism is highly parallelized, allowing the model to process multiple elements simultaneously, significantly improving its computational efficiency compared to traditional sequential models.
By leveraging the power of self-attention, Transformers can effectively capture the intricate relationships and dependencies within language, enabling LLMs to generate highly coherent and contextually relevant text. This architectural innovation has been a driving force behind the remarkable performance of modern LLMs, pushing the boundaries of what is possible with natural language processing.
Training LLMs: The Importance of Data and Compute Power
While the transformer architecture and attention mechanisms are the architectural foundations of LLMs, their true power lies in the massive amounts of data and computational resources required to train them effectively.
Training an LLM is akin to feeding a voracious reader an entire library's worth of books, articles, and texts, allowing it to absorb and learn from the vast expanse of human knowledge contained within. However, unlike a human reader, an LLM can consume and process this information at an unprecedented scale and speed.
The training data for these models is often measured in terabytes or even petabytes, encompassing a staggering breadth of textual information from various sources, such as websites, books, academic papers, and digital repositories. This massive data corpus serves as the foundation upon which the model builds its understanding of language, concepts, and relationships.
Imagine trying to learn a language solely from a handful of short phrases – your understanding would be severely limited. However, by exposing LLMs to billions upon billions of words and sentences spanning countless topics and contexts, these models can develop a rich and nuanced comprehension of language that rivals, and in some cases surpasses, human capabilities.
But processing and learning from such vast amounts of data is no small feat. It requires immense computational power, often harnessing the capabilities of thousands of specialized processors working in parallel. These massive computing clusters, commonly referred to as "training rigs," consume vast amounts of energy, generating enough heat to warm entire office buildings.
The training process itself is an iterative and resource-intensive endeavor, with each cycle of weight and parameter updates requiring billions or even trillions of calculations. It's a computational marathon that can span weeks or even months, pushing the limits of modern hardware and infrastructure.
Yet, the investment in data and compute power pays off in the form of LLMs that can understand and generate human-like text with remarkable fluency and coherence. These models are not merely parroting memorized phrases but rather demonstrating a deep understanding of language, context, and concepts – a feat made possible by the vast scales of data and computational resources employed in their training.
Applications and Impact of LLMs
The remarkable capabilities of large language models have already begun to reshape various industries and domains, with their applications spanning from language translation and content creation to customer service and data analysis.
One of the most prominent applications of LLMs is in the realm of language translation. By training on multilingual datasets, these models can effectively translate between languages while preserving the nuances, idioms, and context of the original text. This has immense implications for breaking down language barriers and facilitating global communication.
Content creation is another area where LLMs are making significant strides. From generating news articles and creative writing to drafting marketing copy and even coding, these models can produce human-like text tailored to specific tasks and styles. This not only enhances efficiency but also opens up new avenues for creative expression and collaboration between humans and AI.
Question-answering systems powered by LLMs are also gaining traction, enabling users to obtain accurate and relevant information by posing natural language queries. This technology has applications in customer service, research, and education, empowering users to access knowledge more intuitively and efficiently.
However, as with any transformative technology, the rise of LLMs raises important ethical considerations. Concerns surrounding bias, privacy, and the potential misuse of these models for spreading misinformation or generating harmful content must be addressed proactively.
Additionally, the increasing reliance on LLMs raises questions about the future of certain professions, such as writing and translation, and how these models will impact human creativity and self-expression.
As LLMs continue to evolve and become more integrated into various aspects of our lives, it is crucial to strike a balance between harnessing their potential and mitigating their risks. Responsible development, ethical guidelines, and a deep understanding of the societal implications will be essential in ensuring that these language models are leveraged for the betterment of humanity rather than its detriment.
Conclusion
Through this exploration of large language models, we've uncovered the fascinating mechanisms that enable these AI systems to understand and generate human-like text with remarkable fluency and coherence. From the building blocks of neural networks to the ingenious transformer architecture and attention mechanisms, we've witnessed the intricate interplay of computational components that underpin LLMs' linguistic prowess.
We've also delved into the immense scale of data and computational resources required to train these models effectively, highlighting the staggering volumes of textual information and vast computational power that fuel their learning process. This immense investment of resources is a testament to the transformative potential of LLMs and the drive to push the boundaries of natural language processing.
As we've discussed, the applications of LLMs are far-reaching, spanning language translation, content creation, question-answering systems, and beyond. These models are poised to reshape industries and facilitate more intuitive and efficient interactions between humans and machines.
However, as with any powerful technology, the rise of LLMs also raises important ethical considerations. Issues surrounding bias, privacy, and the potential misuse of these models must be addressed proactively, ensuring that their development and deployment are guided by responsible and ethical principles.
The journey to unraveling the inner workings of large language models is far from over. As research continues to advance and new breakthroughs emerge, our understanding of these linguistic marvels will deepen, paving the way for even more remarkable applications and capabilities.
For those eager to further explore the fascinating world of LLMs, I encourage you to delve into the wealth of resources available, including academic papers, online courses, and the growing body of literature on this topic. Stay curious, stay engaged, and embrace the exciting possibilities that lie ahead as we continue to unlock the potential of these language wonders.