
How to Generate High-Quality Audio with ModelsLab’s Text to Audio
Written on . Posted in AI.
ModelsLab’s Text-to-Audio API is a powerful tool that transforms your written text into clear, natural-sounding speech with ease. Whether you're creating voice-overs for ads, crafting educational content, or developing interactive media, ModelsLab’s technology offers the best solution.
The speech and voice recognition market is booming, with a projected growth from $9.4 billion in 2022 to $28.1 billion by 2027. This rapid expansion highlights the growing importance of voice-driven tech. By integrating ModelsLab’s Text-to-Audio API into your projects, you can stay ahead of the curve and offer innovative, engaging audio experiences.
In this guide, we’ll show you how to get started with ModelsLab’s tool, troubleshoot common issues, and answer your top questions. With our tips, you'll be ready to produce professional-grade audio quickly and efficiently.
Learning Objectives:
Understand the basics of text-to-audio technology and its functionality.
Familiarize yourself with ModelsLab's Text-to-Audio API, including its key features and benefits.
Set up a ModelsLab account and obtain an API key.
Learn to generate audio from text prompts using the ModelsLab dashboard and API.
Explore advanced features such as customization options, batch processing, and integrating audio into workflows.
Troubleshoot common issues related to API keys, audio generation, and integration.
Discover various use cases for text-to-audio technology across different industries.
What is ModelsLab’s Text-to-Audio API?
ModelsLab's Text-to-Audio API is a tool that converts written text into high-quality, natural-sounding audio. By inputting text prompts, users can generate clear and realistic audio files without needing advanced technical knowledge or expensive hardware.
The API uses advanced AI technology to produce audio that accurately reflects the given text.
Key Features and Benefits:
High-Quality Audio Generation: Produces clear and natural-sounding audio with different emotions from text prompts.
Ease of Use: User-friendly interface that simplifies the audio creation process.
No Advanced Hardware Required: All computational tasks are managed by the API, removing the need for specialized hardware.
Versatile Applications: Suitable for creating various audio content, from voiceovers to interactive media.
Fast and Efficient: Delivers high-quality audio promptly, facilitating quick iterations and updates.

How Text-to-Audio Technology Works
Text-to-audio technology converts written descriptions into spoken content. The process generally involves several steps:
Text Analysis: The input text is parsed to understand its content, tone, and context.
Audio Synthesis: AI models convert the text into audio, ensuring it aligns with the intended message and tone.
The technology relies on advanced AI models, such as Text-to-Speech (TTS) engines, that are trained on extensive datasets to generate lifelike speech patterns and intonations. Learn More about Text-to-Speech.
Getting Started with ModelsLab's Audio Generation
Step-by-Step Guide to Sign Up
Visit the ModelsLab
Sign Up: Click on the "Sign Up" or "Get Started" button on the homepage.
Provide Information: Enter your email address, create a password, and provide any required details like your name and organization.
Verify Your Email: Check your email inbox for a verification message from ModelsLab and click the provided link.
Log In: Return to the ModelsLab site and log in with your new credentials.
Generate Audio in the Playground using Audio Gen
Access the Playground: Click on "Playground" in the dashboard header to enter the Playground environment.
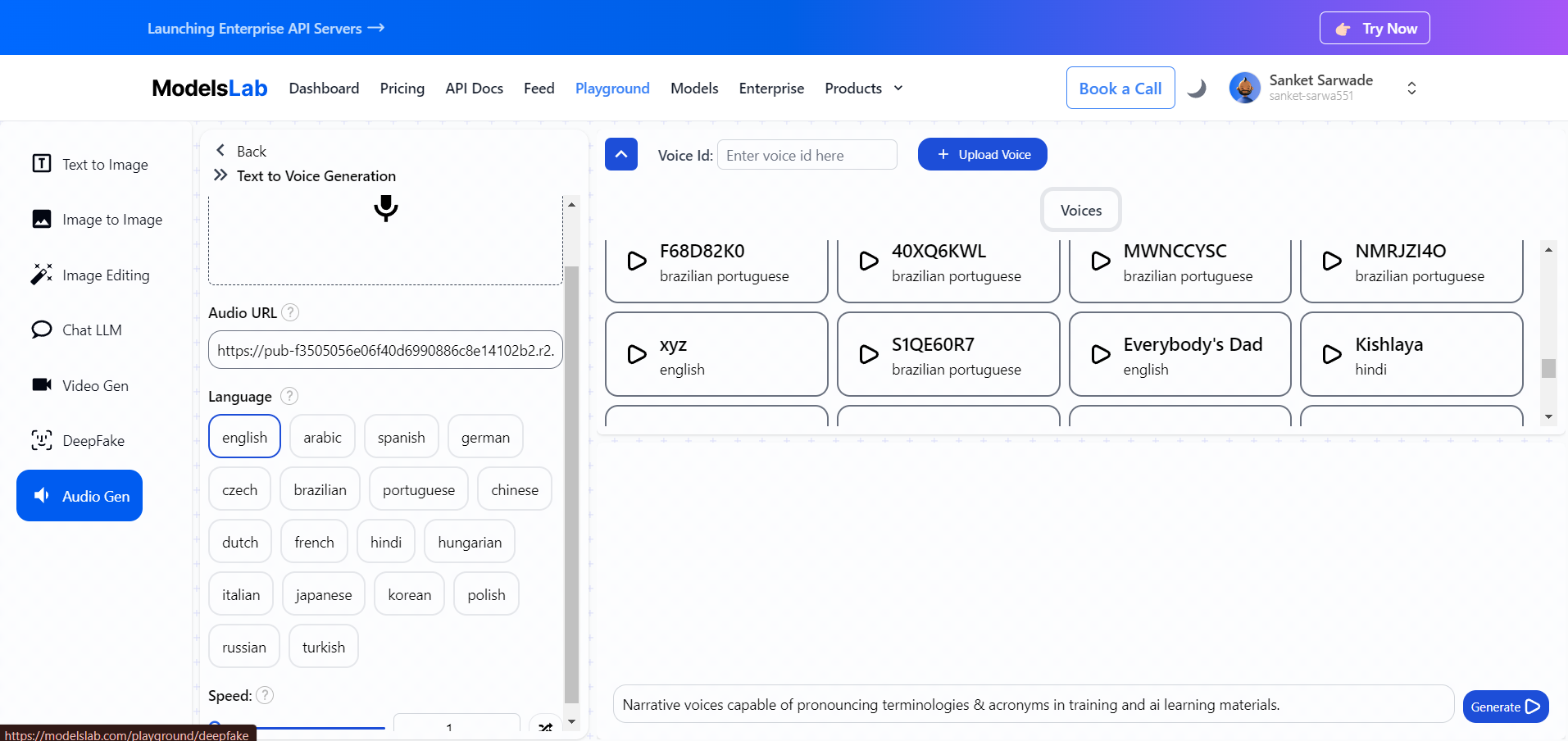
Select the Audio Generation Tool: Locate 'Audio Gen' and select the "Text-to-Audio" option from the available tools.
Upload Your Model: If you have a specific voice model you want to use, you can upload it to generate speech in that particular voice.
Select a Voice Model: Alternatively, choose a voice model from the provided list using its Voice ID.
Set Language, Speed, and Emotions:
Language: Choose from over 18 supported languages. You can also customize the language options by training your own model if needed.
Speed: Adjust the Speed according to your needs.
Emotions: Adjust the Emotions of the speech to match your requirements. (neutral, happy, sad, angry, dull)
Write the text/script you want to convert into voice in the provided text box.
Generate the Audio: After configuring the settings, click on "Generate" to create the audio.
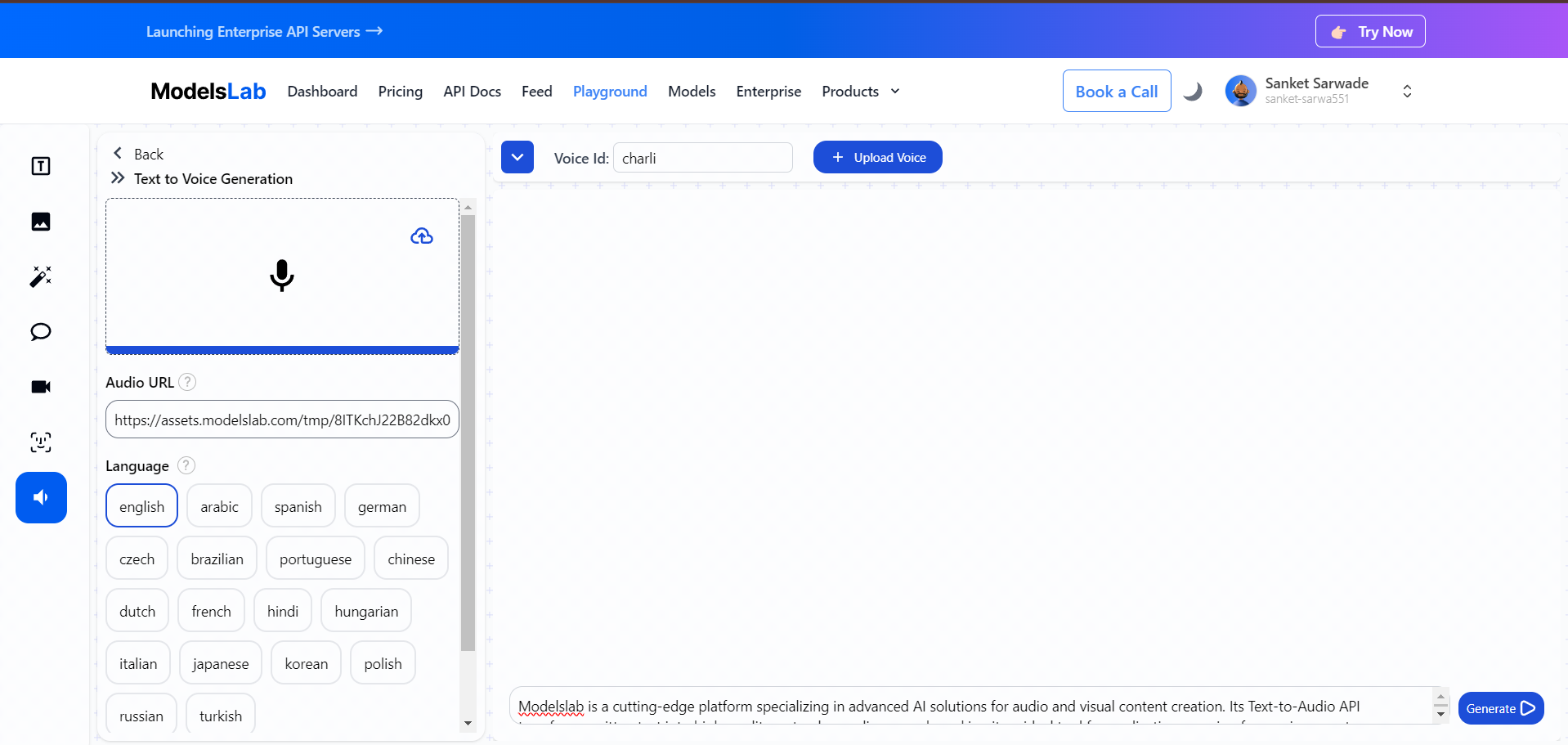
Download or Play: Once the audio is generated, you can listen to it directly or download it for later use.
Using the Text-to-Audio tool in the Playground allows you to easily convert text into high-quality speech. Whether you want to use a predefined voice model or upload a custom one, and no matter what language or speed you require, the Playground offers flexibility and customization options to meet your needs.
For further customization, consider training your voice model to achieve specific characteristics or accents. Enjoy the creative possibilities with the Text-to-Audio tool!
Integrating ModelsLab Text to Audio via API
Setting Up API Access and Generating Audio
Navigate to API Settings: Go to "My Account" > "Admin" > "API Settings".
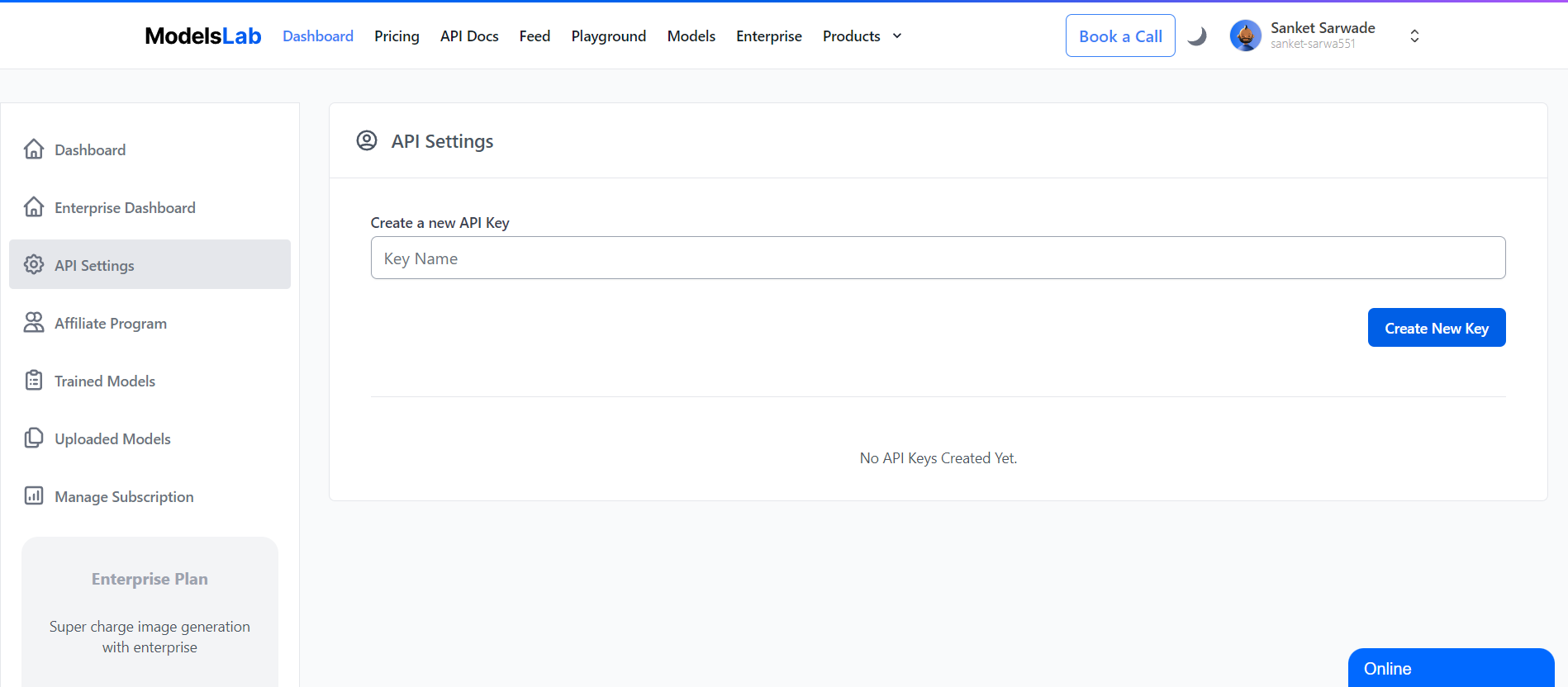
Create API Key: Click on "Create New API Key" and follow the instructions.
Access API Documentation
Visit the API Documentation: Refer to the API documentation provided by ModelsLab.
Use Postman for API Requests: Open Postman to make API requests.
Making the POST Request
Endpoint: Make a POST request to https://modelslab.com/api/v6/realtime/text2audio.
Request Body: Include the required parameters as specified in the documentation.
Configure the Request
Select and Specify Request: Open Postman and navigate to the "Body" tab, where you can specify the content of your request. In the "Body" tab, select "raw" from the available options and then choose "JSON" from the dropdown menu. This sets the format for the data you will send.
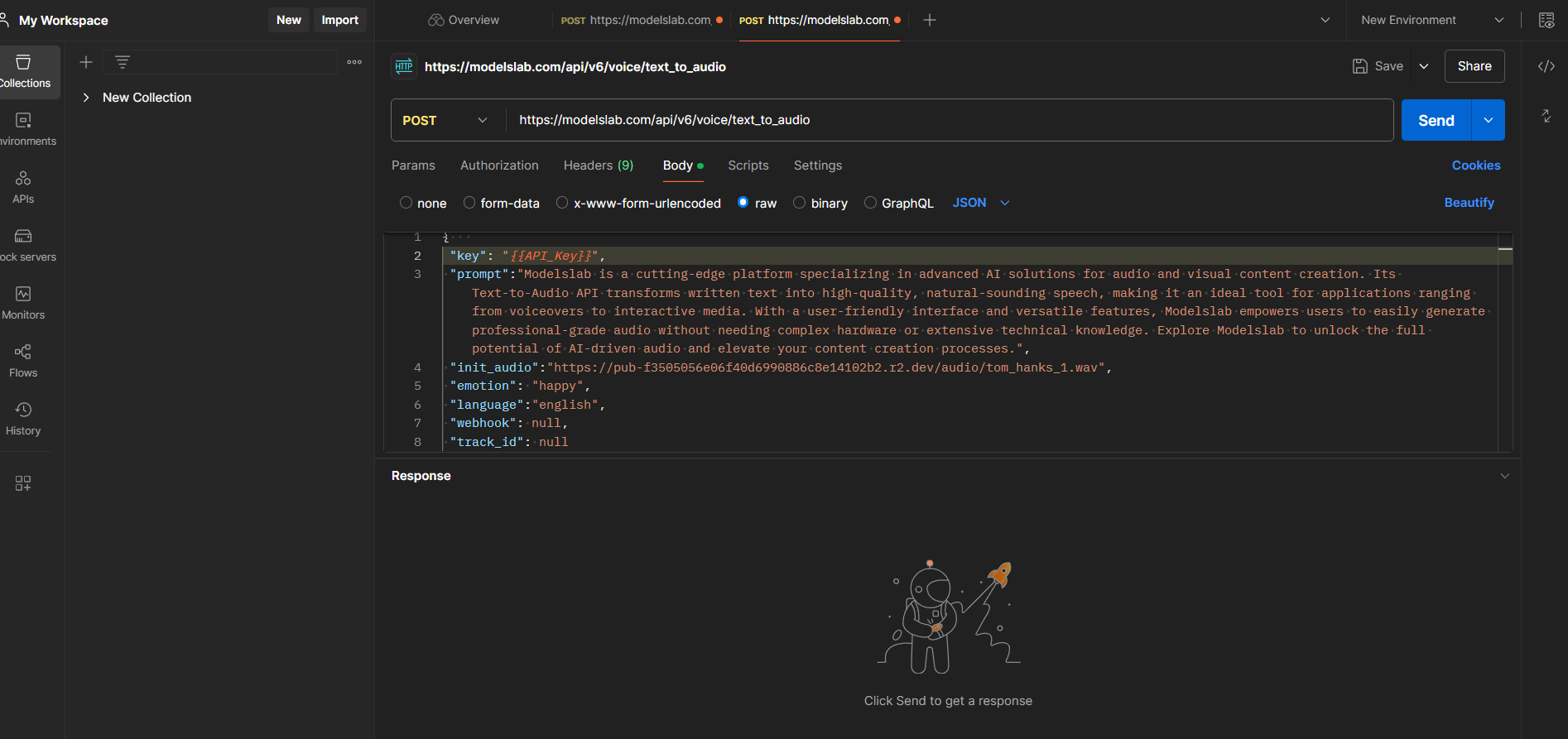
Insert API Key: Copy the JSON body template from the API documentation. In the template, insert your API key within double quotes.
Update Parameters: Modify the parameters as needed for your specific use case. Here is a list of parameters.
Send the Request: After configuring the body of your request, click the "Send" button to execute the request. Wait a few seconds for the server to process it and return a response.
Output: Once the request is complete, click on "Output" in the response section. Ensure the request method is set to POST and the API key is included. After clicking the link, you can download the audio file for your use.
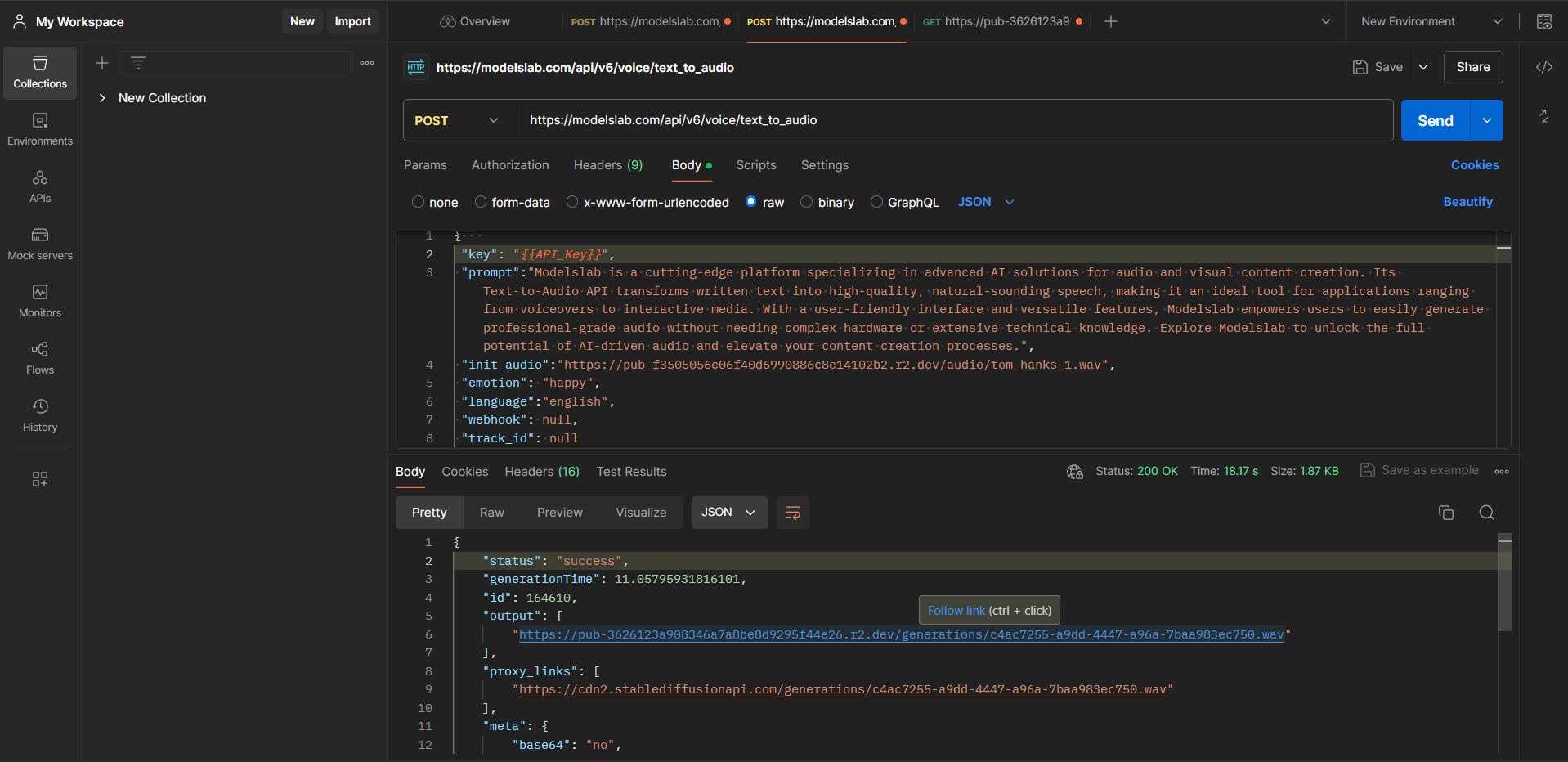
You’ve now successfully set up the API request and generated audio using ModelsLab’s Text-to-Audio API!
Why Choose Our Text-to-Audio Generation
Choosing ModelsLab’s Audio Generation for text-to-audio offers several compelling advantages:
High-Quality Output: ModelsLab delivers clear, natural-sounding audio that closely mimics human speech, ensuring your content sounds professional and engaging.
Emotions: Choosing ModelsLab’s Audio Generation for text-to-audio brings several key benefits, including the ability to adjust the emotional tone of your audio output. Whether you need a happy, neutral, sad, angry, or dull tone.
User-Friendly Interface: The platform is designed for ease of use, allowing both novices and experts to quickly generate audio without needing specialized technical skills. You can upload your own model.
Versatility: With support for various languages, voice models, and customization options, ModelsLab accommodates a wide range of applications, from marketing voiceovers to interactive media.
No Advanced Hardware Required: The service manages all computational tasks on its servers, eliminating the need for costly hardware and making it accessible from any device.
Efficient Processing: Modelslab's API provides fast and reliable audio generation, facilitating quick turnaround times for your projects and enabling rapid iterations.
Customization: Users can choose or upload specific voice models, adjust speech speed, and tailor the audio output to align with their unique requirements.
Try ModelsLab's Voice cloning and Voice generation API!
Use Cases of Text-to-Audio Generation
Text-to-Audio technology is versatile and applicable across various industries. Here are some common use cases:
Marketing and Advertising
Voiceovers for Ads: Create compelling and engaging voiceovers for television and online advertisements.
Promotional Materials: Generate audio content for promotional videos, radio spots, and marketing campaigns.
Interactive Campaigns: Use text-to-audio to create interactive voice responses for marketing campaigns, making them more dynamic and engaging.
Content Creation
Blogs and Articles: Convert written content into audio for blogs, reaching a wider audience.
Educational Videos: Produce narration for educational videos, making complex subjects more accessible.
Podcasts: Create audio content for podcasts, saving time on recording and editing.
E-Commerce
Product Descriptions: Generate audio descriptions for products on e-commerce sites, improving accessibility and user experience.
Customer Support: Develop interactive voice responses for customer support systems, providing instant assistance and information.
Gaming and Entertainment
Character Voices: Create distinctive voices for game characters, enhancing the gaming experience.
Game Dialogues: Generate dialogues and in-game announcements, making games more immersive.
Interactive Narratives: Develop interactive audio narratives for story-driven games and applications.

Education and Training
E-Learning Modules: Produce audio content for online courses and training programs, aiding comprehension and retention.
Educational Content: Create audio versions of textbooks and educational materials for students with visual impairments or learning disabilities.
Training Materials: Develop audio guides and instructions for various training programs, enhancing the learning experience.
Troubleshooting and FAQs
Troubleshooting Common Issues
API Key Errors
Issue: You receive an error related to the API key.
Solution: Ensure your API key is valid and correctly included in the request. Double-check the key in your account settings.
Audio Generation Glitches
Issue: The generated audio is not as expected or has glitches.
Solution: Verify your request parameters, including text and audio settings. Consult the API documentation for correct parameters and try regenerating the audio.
Low Processing Times
Issue: The audio generation is taking longer than expected.
Solution: Check the server load and rate limits. If issues persist, contact ModelsLab support for assistance.
Quality of Generated Audio
Issue: The quality of the generated audio is not satisfactory.
Solution: Adjust the voice and tone settings in your request. If problems continue, contact support for further assistance.
Frequently Asked Questions (FAQs)
How do I obtain an API key for ModelsLab’s Text-to-Audio service?
Answer: Log in to your ModelsLab account, navigate to "My Account" > "Admin" > "API Settings", and create a new API key.
What audio formats are supported?
Answer: The API supports common formats such as MP3 and WAV. For specific details, consult the API documentation.
Can I customize the voice of the generated audio?
Answer: Yes, you can choose from various voice styles and accents. For custom voice options, contact ModelsLab support.
How do I change Emotions?
Answer: Adjust the Emotion parameter in your API request to generate audio accordingly. Refer to the API documentation for detailed instructions.
What if I encounter an issue not covered in the FAQ?
Answer: Contact ModelsLab support with detailed information about the issue. Provide as much context as possible to receive appropriate assistance.
Conclusion
ModelsLab’s Text-to-Audio API is an advanced tool designed to effortlessly convert written text into high-quality, natural-sounding audio, making it an invaluable resource for a variety of applications. From creating compelling voiceovers and educational content to enhancing e-commerce and gaming experiences, the possibilities are endless.
As the speech and voice recognition market continues to expand, now is the perfect time to use this technology. By integrating ModelsLab’s Text-to-Audio API into your projects, you can stay ahead of the curve and offer innovative, engaging audio experiences.
Don’t miss out on the opportunity to enhance your projects with text-to-audio technology. Explore ModelsLab’s solutions now and transform your text into high-quality audio that resonates with your audience. Sign up for free!